

Introduction
Imagine diving into the dynamic world of League of Legends, where each patch brings thrilling updates and strategic shifts. Now, envision the challenge of translating these detailed patch notes for a global audience, ensuring every player, no matter their language, stays in the loop.
Welcome to our Machine Translation (MT) pilot program. Alongside my teammates, I am embarking on a project to train a neural machine translation (NMT) engine specifically for translating League of Legends patch notes from English into Korean. Our goal is to push the boundaries of NMT technology to see if we can achieve high-quality translations with minimal human intervention.
Through this pilot, we seek to understand the complexities of game-specific terminology and the nuances of patch note content. By training and refining our NMT engine, we aim to reduce the reliance on human translators, speeding up the process and maintaining the excitement and clarity of each update. Join us as we explore the potential of NMT to revolutionize game localization and enhance the player experience for millions of League of Legends fans.
Pilot Project Proposal
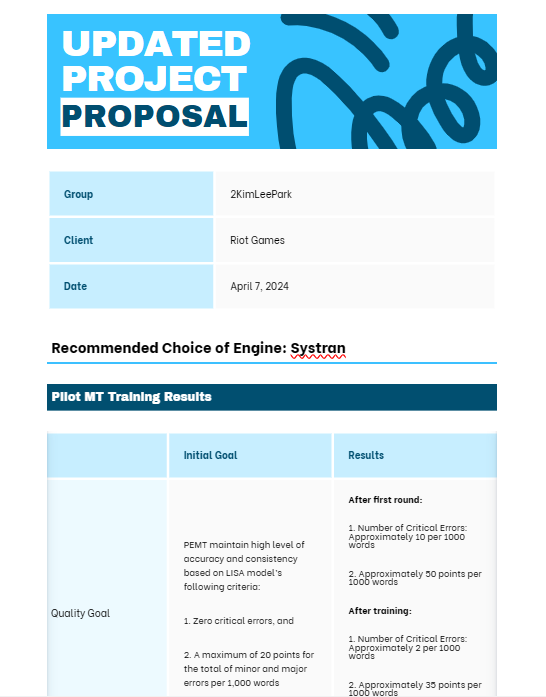
You can view the PDF of the proposal here.
Our initial proposal includes a detailed plan for the MT pilot project, outlining the objectives for quality, timing, and pricing. It specifies the project timelines and processes required for training the MT engines, provides detailed information about the datasets, and includes the expected quotes for the project.


Project Process
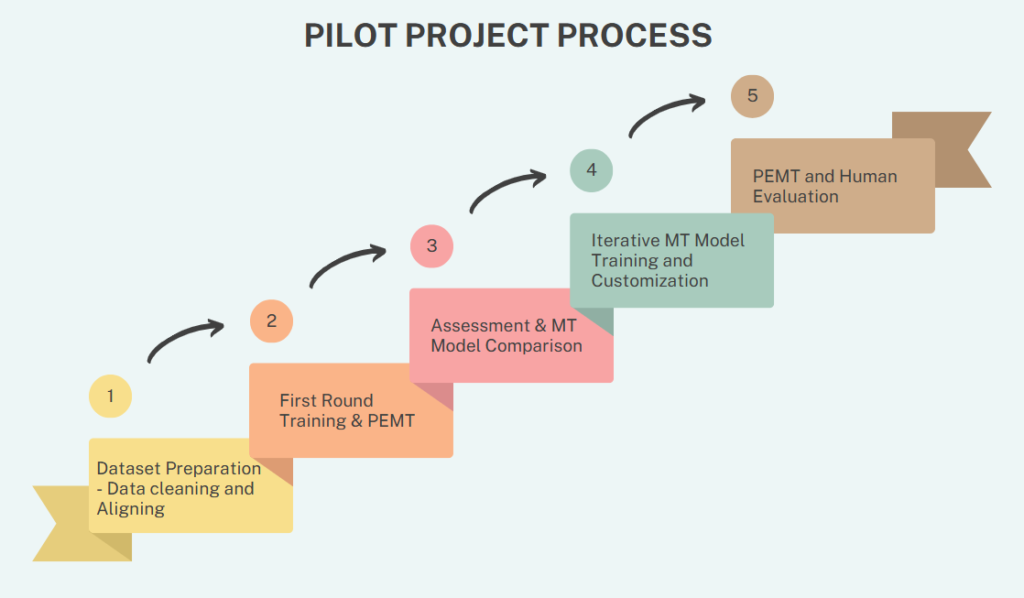
File Preparation
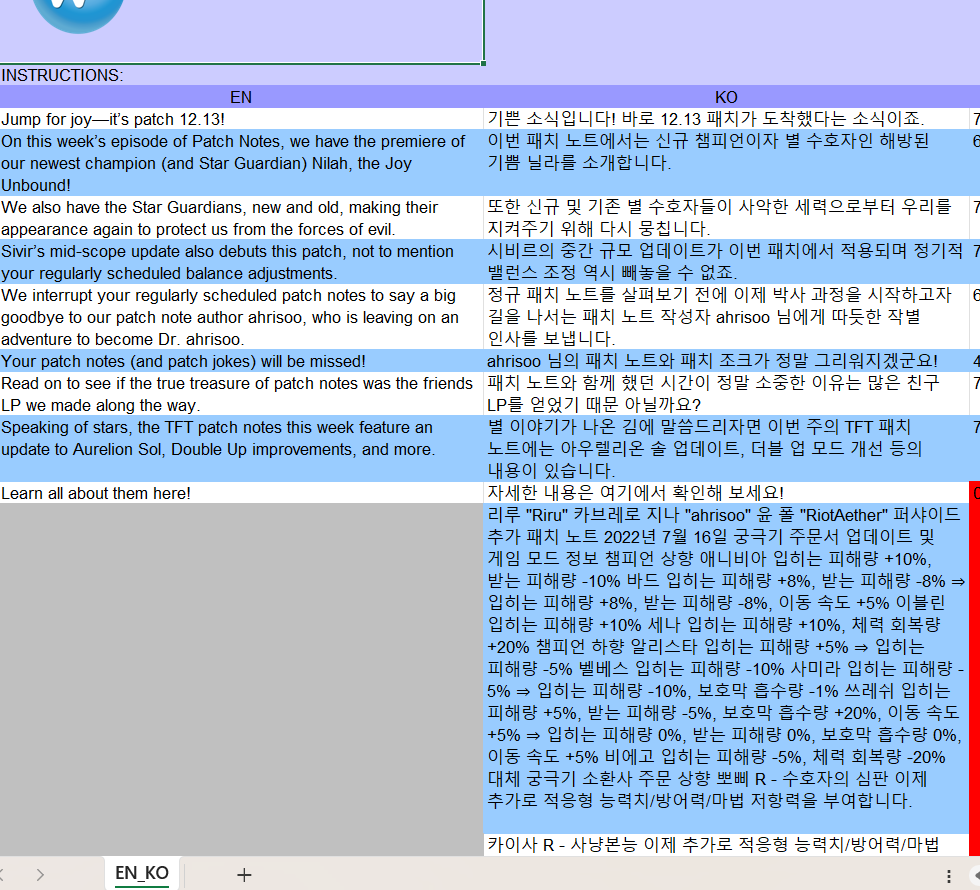
1. Developing Crawlers to Extract Text for Translation
Thanks to a successful collaboration between one of my teammates and a skilled software engineer, we developed crawlers to extract text from the League of Legends website. This innovative automated tool efficiently gathers text content from web pages, converting it into TXT files ready for translation. The use of crawlers not only streamlined the extraction process but also significantly reduced the time required to prepare the text for our translation efforts. With our TXT files ready, we converted them into TMX format to align them using TMX editors.
2. Data Cleaning and Aligning
The process of data cleaning and aligning was crucial to ensure the quality of our translations. We used TMX editors like Wordfast AutoAligner and Okapi Olifant to align the extracted text. Despite the capabilities of these tools, the alignment process was time-consuming and required significant manual effort to achieve accurate results.
To clean the data, we employed simple Regex to remove unwanted elements and ensure consistency. We also deleted extremely long sentences that could compromise the translation quality. These steps were vital to prepare clean, well-aligned datasets for training our NMT engine, ultimately enhancing the efficiency and effectiveness of our translation process.
First Round of Training & Post-Editing
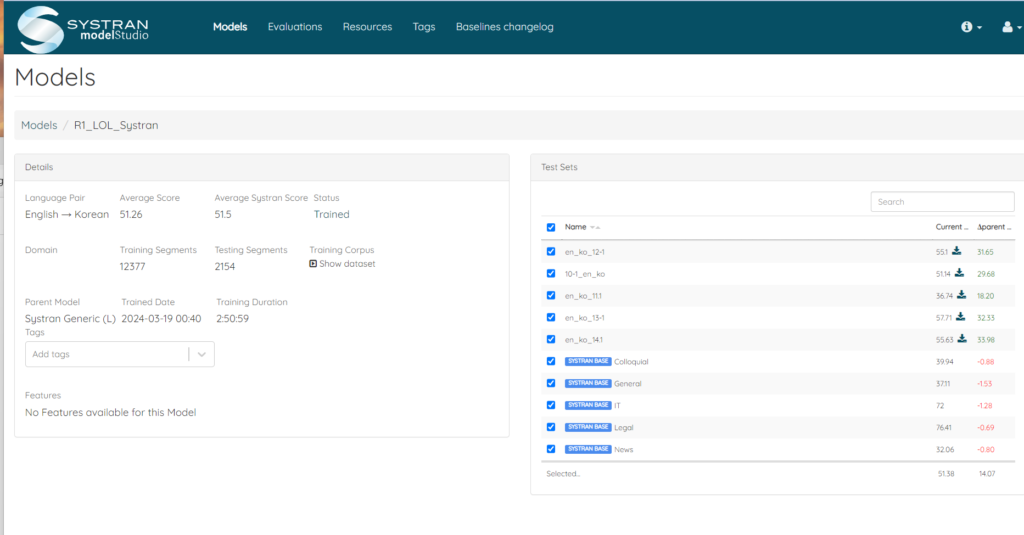
Finally, we are ready for our first MT training. To compare performance, we tested both Microsoft Custom Translator and Systran. After evaluating both models, we decided to proceed with Systran due to its higher BLEU scores and user-friendly interface.
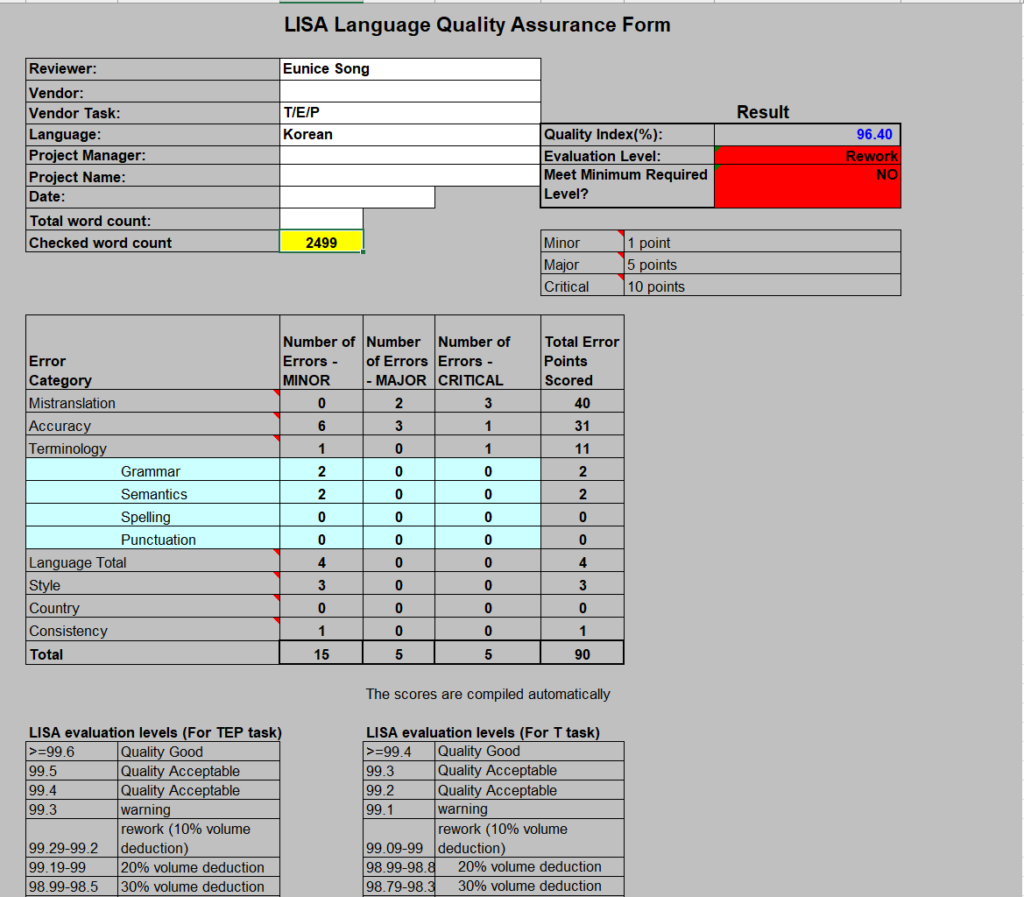
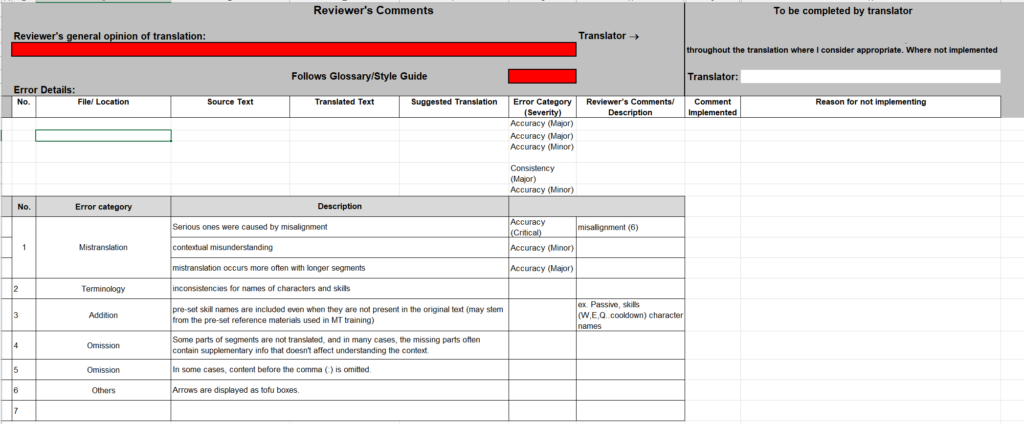
Next, it was time for post-editing machine translation (PEMT). We assigned three team members to conduct human evaluations and tracked the word count they post-edited in a two-hour period. To ensure consistent quality assessment, we used the LISA quality model.
Iterative MT Training (Systran)
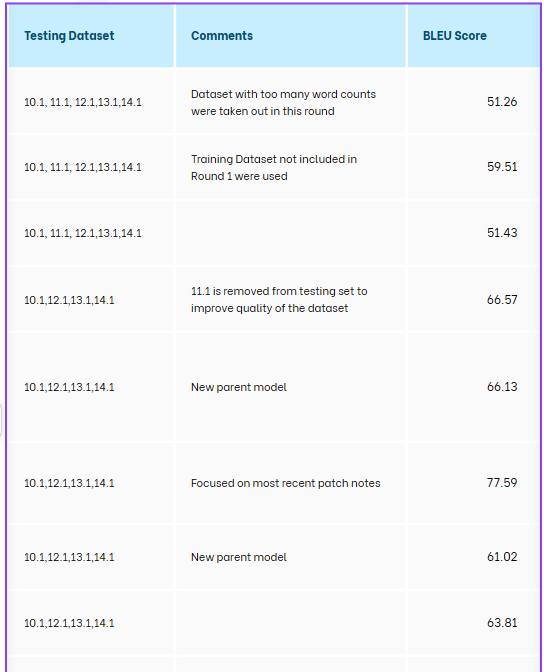
We embarked on a series of 10 training rounds with Systran. After each round, we huddled together to plot our next move, all in the name of boosting those BLEU scores. Our tactics varied from adding more data to the test dataset, to improving our cleaning and aligning processes, and even to using only the crème de la crème of relevant data.
We started strong with relatively high BLEU scores, which set our expectations sky-high. But, to our surprise, more data didn’t always translate to better results. In some cases, things got messy, and the quality scores actually dropped.
We experimented with every trick in the book to train our MT engine. Along the way, we learned that quality data and meticulous refinement are the real magic ingredients.
Final PEMT and Human Evaluation
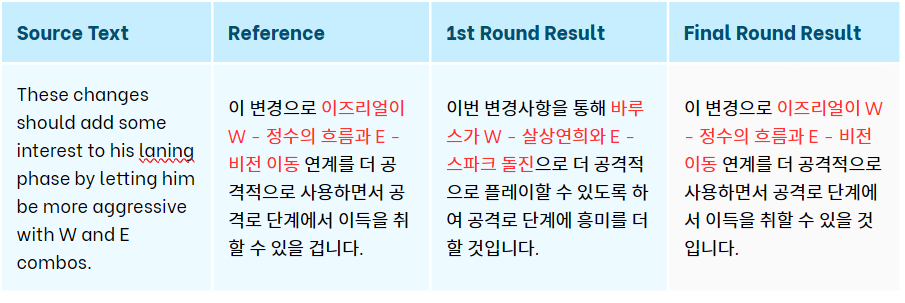
After the final round of MT training, we rolled up our sleeves for another round of PEMT and human evaluation. To keep things consistent, our trusty team of evaluators was back at it. We wanted to see just how efficient our MT engine had become, so we crunched the numbers on how many more words we could edit post-training.
And the results? Drumroll, please… The quality of the MT engine soared! We can now save a ton of time and money on translations.
Want the juicy details? Our updated proposal has all the good stuff: the final BLEU scores, the cash we’ll save, and the hours needed for the full training. Intrigued? Check it out here!
Enjoy our video presentation!